
Published on 2 February 2021




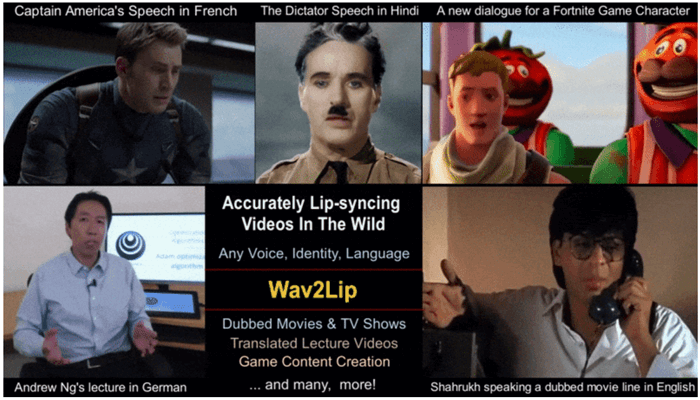
Prajwal K R and Rudrabha Mukhopadyay, researchers at the Centre for Visual Information Technology, International Institute of Information Technology Hyderabad (IIITH) under the guidance of Prof. C V Jawahar and Prof. Vinay Namboodiri (University of Bath) are using a sophisticated AI framework and technique that enables one to synchronize lip movements of a person in a video to match it with any audio clip.
The IIITH AI model can be applied to create videos of any face, in any voice or language throwing open endless possibilities. While the implications for entertainment are mind-boggling, there’s something even closer to Prof. Jawahar’s heart that has spurred this particular research in the first place and that is using AI in the context of education. With his vision of easy availability and access to educational online content to all, the professor is of the opinion that language should be the least of the barriers to gaining knowledge.
Thanks to this technology, well-made lectures by prominent professors or experts on certain topics can be translated into any language of your choice. Or better still, highly accented English videos themselves can be recreated into an accent more comprehensible to the Indian populace.
In the current context of a wholesale virtual education across the country, the technology has the potential in making education more inclusive, especially for rural students. In situations where there is low internet bandwidth and other connectivity issues, lessons with only audio content can be streamed while the AI algorithm could generate the corresponding video accurately matching the original audio.
Such a novel approach can make the learning experience a fulfilling one. In a world where online interactions are the new normal, the researchers foresee its applications in video calls and conferencing where the tech comes to the rescue in case of video glitches. That is, if the incoming video signal is lost, the AI model can automatically plug in a synthetic video with accurate lip sync, enabling the work-from-home situation.





